In silico Alternative Proteins: A short survey
Akhil Jalan
Department of Computer Science, UT Austin
September 1, 2023
Last updated: October 6, 2023.
Table of contents. Readers are encouraged to skip to the list of problems, as it is the most important section.
- Who is this document for?
- Why does it matter?
- Why is there a skills gap?
- List of problems
- Active learning and experimental design
- Protein Engineering in silico
- Bioinformatics and multi-omics models
- Bioprocess state estimation and control
- Computational Fluid Dynamics for exploratory and digital twin modeling
- 3D Models for Adherent Cell Cultures and Scaffolds
- Models for Texturization and Extrusion
- Other Topics
- Concluding thoughts
- About the author
- Acknowledgments
Who is this document for?
This document is a (short, incomplete, and very arbitrarily selected) survey for scientists and engineers that are newcomers to the alternative proteins field but lack a background in biology, chemistry, or other “wet lab” disciplines. Our target audience includes statisticians, computer scientists (such as the author), mathematicians, physicists, electrical engineers, mechanical engineers, etc.
Why does it matter?
The field of alternative proteins (“alt proteins”) has exploded in the past decade. In my opinion, this food technology is a crucial component of the societal transition away from factory farming and industrialized animal agriculture, which are serious contributors to greenhouse gas emissions, deforestation, land use, water use, and detrimental to human health.
There now exist many academic labs and startups in the alt proteins space. However, their technical staffs consist mainly of experts in biology, chemistry, or related fields (the “wet lab” disciplines). As the field of alt proteins matures and scales it will also need expertise from beyond these disciplines to succeed. Quoting a recent report by the Good Food Institute:
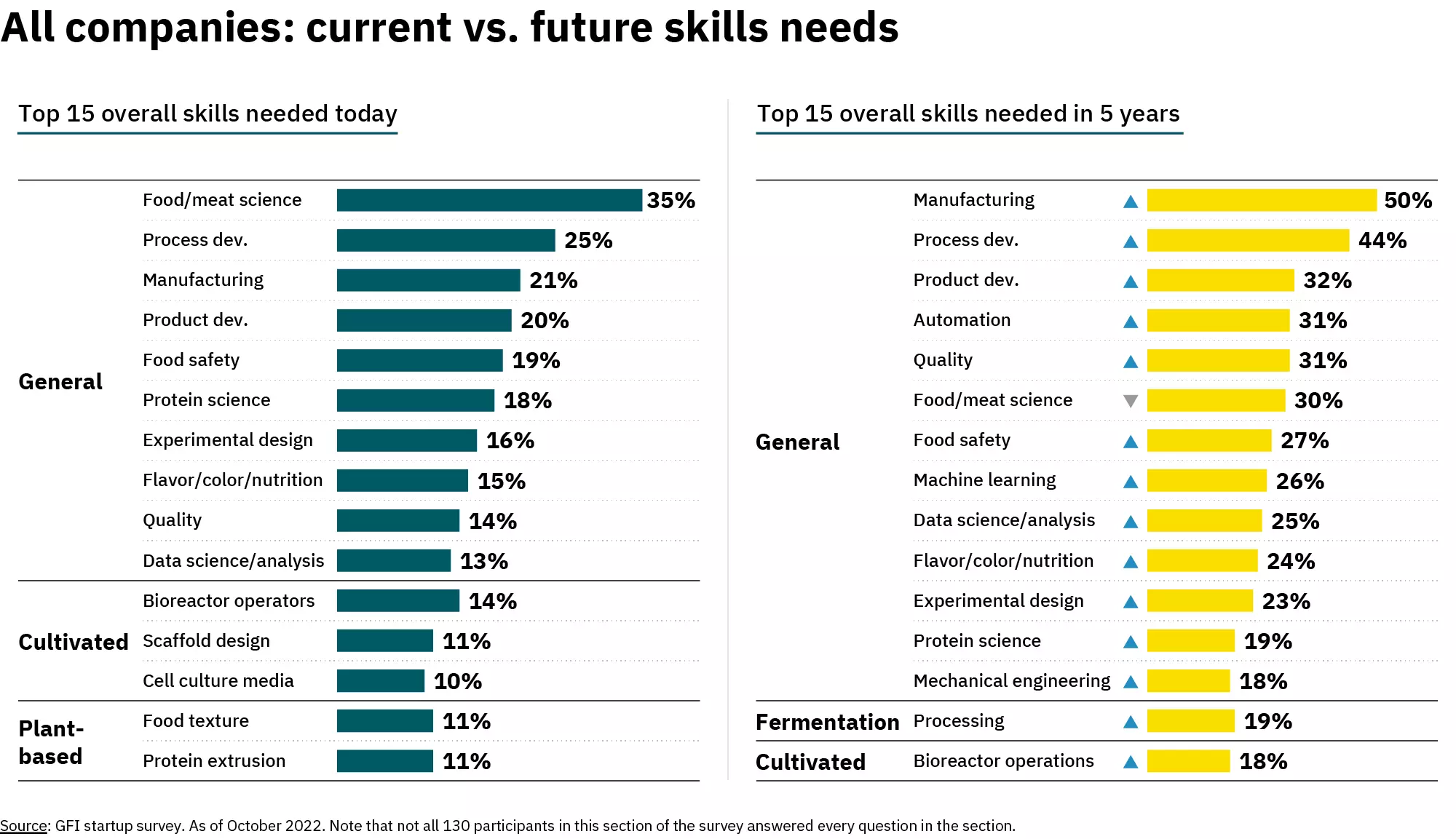
Data from the report highlight an increasing need for machine learning, data analysis, experimental design, protein science, and several more specialized technical areas that I will touch on below.“94% viewed technical talent bottlenecks as posing “very severe” or “moderately severe” challenges to their organization’s long-term success. Beneath the umbrella of technical talent, there is an especially significant need for an infusion of scientific and engineering talent to bolster the sector’s research and development capacity…we expect the nature of talent needs to shift as the sector matures and increasingly transitions toward commercial-scale production when the plurality of the technical workforce will likely become manufacturing operators and technicians rather than benchtop scientists.” (Emphasis mine).
Why is there a skills gap?
Unfortunately, there is no clear path into the field for technical people without wet lab backgrounds. There are good reasons for this, some of which GFI discuss. In addition to their points, I would add the following:
- Alt proteins is a relatively small field even in 2023, and most companies are focused on getting working products and funding rather than the scale-up and optimization work that requires more specialized technical expertise. Specialization occurs after scaling. For example, it does not make sense to hire a data scientist until a company actually has data.
- Alt proteins work is inherently interdisciplinary and has its foundations in bioengineering and chemical engineering. Therefore it makes more sense to recruit people from these pools. If a biologist knows no statistics, they can still go about the day-to-day work of cell culture without much trouble. But a statistician who knows no biology cannot do useful work at most of the companies and labs that currently work on alt proteins.
- There is a widely documented “Two Cultures” divide between the math-heavy and non math-heavy fields of the sciences (to put it very crudely). Of course many people do genuine and exciting work across this divide; some of them have the title of ‘computational biologist’ or ‘biostatistician.’ Nevertheless, the foundational ideas of biology are not nearly as wedded to mathematics and quantification as those of e.g. physics.
What should a “dry lab” scientist or engineer do?
Interdisciplinary work is not for the faint of heart. While I believe there are important and technically rich problems in alt proteins that will require in silico expertise, I also believe that in applied work, domain knowledge is key. In practice, this means listening carefully to one’s colleagues in the wet lab and working hard to learn their way of thinking and specific technical vocabulary.
Still, I believe that the field needs scientists and engineers from outside of the wet lab disciplines; moreover, I believe that it is not building enough of a talent pipeline for such people. This document attempts to help address this by laying out concrete technical problems that people without wet lab backgrounds can work on. With a better sense of what they might end up doing, motivated people can try to dive deeper on these problems and get involved in the field through full-time employment, consulting, research, or independent work.
Without further ado, let me share some concrete problems.
List of problems
Active learning and experimental design
A universal problem in experimental science is the design of experiments (DoE): given an experimental budget and a function one wants to learn (or a set of hypotheses one wants to test), what experiments are maximally informative? Moreover, if we are allowed to perform many rounds of experiments, how can we adaptively design experiments on the basis of freshly obtained information (this is called “sequential DoE” or “active learning”)?
In alt proteins, researchers have used active learning or DoE to optimize cell culture media: the nutrient broth that cells eat to grow and multiply. Some important papers in this area are Cosenza et al, who use multi-objective Bayesian optimization, and Nikkhah et al, who use genetic algorithms. Note that these two papers came out of UC Davis and Tufts University respectively - both of these institutions are hubs for alt proteins research.

Obviously, active learning has a very broad scope and may be useful beyond just culture media optimization. I would speculate that it is more useful in cases where first-principles models are lacking and one must resort to black box optimization; in particular, in so-called “high throughout” experimental settings.
Key words: Active learning, design of experiments, response surface method, Bayesian optimization, high-throughput experiments
Protein Engineering in silico
The number one cost driver for cultivated meat is cell culture media (see this techno-economic analysis): the nutrient broth that cells eat to grow and multiply. A key component of cell culture media is a cocktail of molecules that perform cell signaling, especially proliferation and development.
Using protein engineering, researchers can design better and cheaper growth factors. For example, researchers developed a variation of Fibroblast Growth Factor 2 (“FGF2-STAB”) using a computational protein engeering pipeline combined with lab experiments. This is now a product offered by the company Enantis. With the advent of AlphaFold and GPT-type tools for sequence modeling, protein engineering is an especially ripe area of application for machine learning; any ML or DL experts should seriously consider pursuing this area further.
Key words: Protein engineering, growth factors, protein thermostability, de novo protein synthesis, molecular dynamics
Bioinformatics and multi-omics models
In addition to purely experimental approaches, researchers use first principles models from bioinformatics to optimize cell culture media and bioprocesses. I would highly recommend the interested reader to this white paper by Van Heron labs (and references therein) for more details. Quoting,
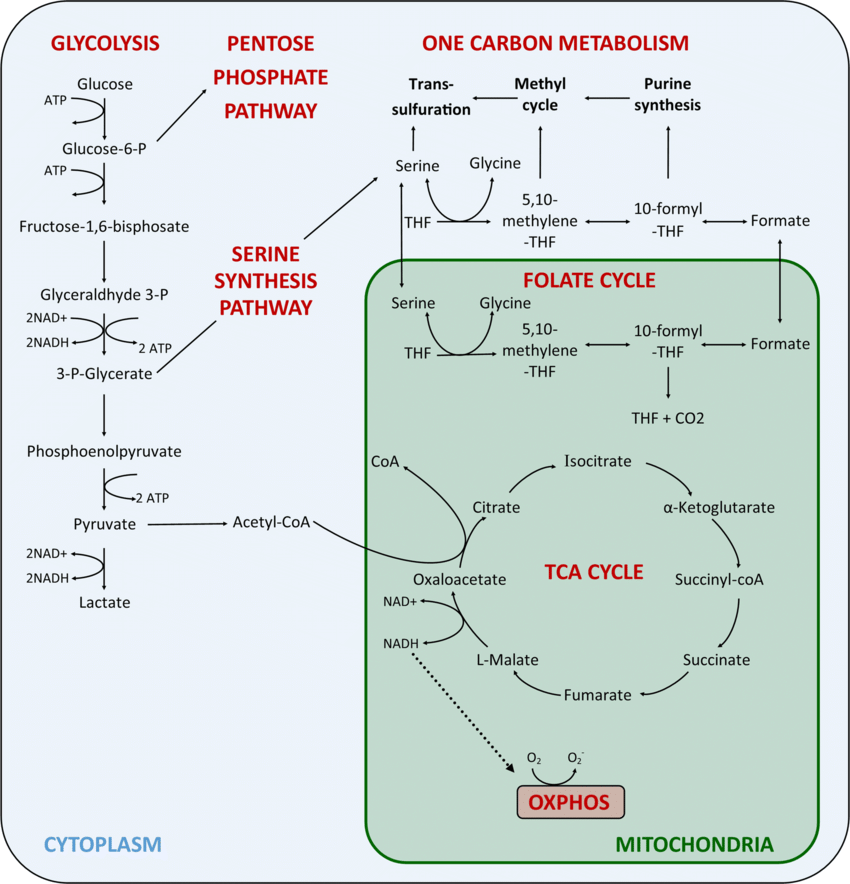
“Van Heron Labs uses omics data, primarily gene-expression data, and computing (bioinformatics and AI) to create better media and feed formulations for cells to increase the productivity/titer and robustness of bio-based processes and applications. The VHL platform uses genetic information as a tool to gain insights into cellular function and determines the most efficient macro and micronutrient inputs…This precision nutrition approach optimizes cellular metabolism, which, in turn, optimizes the bio-process or cell-based application of interest….In silico approaches, such as flux balance analysis and, recently, genome-scale metabolic modeling (GEMs), have been used to assess the metabolites the cells utilize in the highest concentrations. Metabolomics of in-vivo states is often utilized to create more optimal media formulations (Ex., gut metabolomics to create E. coli media, or serum metabolomics to create de-novo media for obscure species/cell types). In silico strategies save considerable experimental effort and accelerate development (Huang et al., 2020)." (Emphasis mine).
Note that the suffix “omics” is a catch-all term that loosely refers to several areas, including genomics, transcriptomics, metabolomics, lipidomics, and others. The most relevant “omics” area for us is “metabolomics,” since we are concerned with how cells grow and develop based on their specific metabolic consumption patterns and waste product creation. However, there is a growing interest in so-called “multi-omics” approaches that combine datasets of multiple types of omics, via e.g. principal component analysis.

These ideas are of course not new, even within cell culture. For example, this 1988 article contains detailed discussion of metabolic pathways in mammalian cells and the efficiency of ATP production through different kinds of metabolic activity.
Key words: Metabolomics, flux balance analysis, stoichiometry, genome scale metabolic models (GEMs), multi-omics, mass spectrometry, nuclear magentic resonance (NMR)
Bioprocess state estimation and control
Controls theory is a broad and old engineering discipline that traces its roots to the operation of steam engines in the 19th century. Put simply, controls refers to the optimization problem of steering a dynamic process towards a desirable outcome - for example, steering a plane through difficult skies with autopilot.
Nowadays, controls is absolutely central to mechanical and electrical engineering, but not as prominent in bioengineering and chemical engineering. Two important reasons for this are the difficulty of state estimation (what is the current state of the process?) and dynamical characterization (how does the process evolve in time?). To wit: the basic physics of steam engines (heat transfer, convention, compression, friction) were understood in the 19th century. The internal workings of a single mammalian cell, however, are far from fully characterized.
Nevertheless, one can make up for a poor understanding of dynamics with an excellent real-time estimate of state. The more detailed and frequent information we have about a bioprocess (or any other black-box process), the more we can approximate its dynamics and steer it towards desirable outcomes.
Therefore, estimating the state of a bioprocess (e.g. a mammalian cell culture for cultivated meat, or a microbial culture for fermentation) is a key step for process optimization. However, there is no tool that can satisfy all of the following desiderata for bioprocesses:
- Full state characterization: It characterizes all of the state variables we care about: Cell viability, density, level of key metabolites and media, pH, dissolved oxygen, etc.
- Continuous Measurement: It takes measurements frequently enough to form a useful real-time state estimate (e.g. every 5 minutes).
- Cheap Measurement: It can be done cheaply, without the need to purchase input ingredients for the sample preparation each time.
- Automatic: It requires no human labor.
- Sterile: The sample preparation or measurement does not introduce a contamination risk.
Nevertheless, promising approaches to cell state estimation abound. We refer the reader to this excellent survey on controls in bioprocessing, which highlights soft sensing as a particularly fruitful direction. A “soft sensor” is one that gives a measurement which contains information about the process state, but not the direct state variables themselves. For example, a smoke detector is a “soft sensor” for fire.
Many soft sensors in biotechnology involve imaging or spectroscopic techniques - see e.g. this paper. Such sensors can be fused with state estimation algorithms such as Kalman filters - for example, as in the works of Andrea Tuveri or Marieke Klijn. Some particular sensor types include dielectric spectroscopy, Raman spectroscopy, and NIR spectroscopy.
State estimation is therefore another statistical problem, but one that may be particularly accessible to those with signal processing backgrounds.
Key words: Quality by control, Process Analytical Technology, soft sensing, IR spectroscopy, dielectric spectroscopy, NIR spectroscopy, IR spectroscopy, in-situ
Computational Fluid Dynamics for exploratory and digital twin modeling
A key aspect of state characterization for bioprocesses is the dynamic properties of fluid and gas mixing due to sparging (introducing oxygen, nitrogen, CO₂) and agitation (e.g. due to the rotation of an impeller in a stirred-tank reactor).CFD is an extremely difficult algorithmic problem that requires both a strong understanding of the underlying mathematics (which are, of course, themselves famously difficult), and also a pretty good programming and algorithmic understanding. Moreover, it is well-motivated, since fluid dynamics are what largely determine mass transfer in bioreactors. Mass-transfer is a key determinant of bioreactor productivity - see e.g. this paper.
CFD modeling is therefore useful as an exploratory design step (e.g. what sparging and agitation conditions to set, what bioreactor designs to use, what additives to use in the culture media) and also in the use of so-called “digital twins” (state estimates) for real-time monitoring.
There are many groups working on CFD modeling for alt proteins - two that I would highlight are the Cultivated Meat Modeling Consortium and Cees Haringa’s group at TU Delft.
The CMMC has tackled the issue of jointly modeling cell dynamics and fluid dynamics by combining CFD with agent-based models for mammalian cells on microcarriers. In that study, a key question was the limits of cell tolerance for shear stress, which is a major concern in large-scale cultures. Agent-based models have the advantage of flexbility, since they can describe many kinds of behavior and cell types provided that they are parametrized with enough data. However, ABMs are computationally intensive at large scales since one needs to perform a forward simulation step for each agent separately, and this is prohibitively expensive if there are billions of cells. While parallelism can reduce the wall time of such simulations, it cannot reduce the overall amount of compute required.

By contrast, Haringa’s group has developed an “organism lifeline” approach with Euler-Lagrange dynamics, which studies the trajectories of specific cells (in this case, microbes) as they travel through different regions of a bioreactor and experience different fluid dynamics regimes over time. By combining this with first principles differential equations models for microbe growth kinetics, they are able to study the effect of different fluid dynamical parameters on overall process outcomes.
In general, CFD will become increasingly important at large scales, and is therefore an important topic to tackle for the industry. Off-the-shelf CFD tools, in addition to being difficult for non-experts to use, are insufficient for jointly modeling the dynamics of fluids and gases with the evolving state of individual cells in microbial or cell culture systems. These problems will require serious multiscale modeling to go beyond the current, largely heuristic applications of CFD.
Key words: Mass transfer coefficient, kLa, shear stress, mixing time, Euler-Lagrange, Navier-Stokes, multiscale modeling
3D Models for Adherent Cell Cultures and Scaffolds
Most of the work mentioned so far analyzes cell culture processes up to and including the cell proliferation stage; the goal, in this step, is to just multiply the cells as much as possible before inducing them to differentiate into more specific cell types such as muscle and fat cells. In this stage, the 3D arrangement and structure of the cells into a food product becomes important, and this raises its own set of challenges.
One method to get a structured 3D product is to use a porous scaffold that cells attach to during development. It is known that having a mass to adhere to (an “extracellular matrix”) encourages development and differentiation of cells.
Understanding the geometric properties of such scaffolds, and their behavior in a fluid dynamics setting, is important to bioprocess development and optimization. Researchers in tissue engineering have developed CAD libraries for this task. Moreover, tissue engineering has studied the issue of porosity in particular, since scaffolds that obstruct the flow of fluid to certain regions will prevent the delivery of nutrients and oxygen to those cells, causing cell death.
Key words; Porous scaffold, extracellular matrix, tissue engineering
Models for Texturization and Extrusion
As in the previous problem, I wish to highlight the importance of modeling for texturization and extrusion technologies. Currently these are used in plant-based meat, and likely in cultivated meat and fermentation products as well.Extrusion, in particular, is poorly understood; the mapping from machine setting to taste and texture outcomes is considered a black box. To remedy this, researchers have used simple statistical approaches to inform data-driven approaches to high-moisture extrusion, such as principal component analysis (PCA). As in the previous black-box problem we saw (cell culture media), I would speculate that combining this purely statistical approach with first-principles understanding and physics models would give better results. For example, this survey highlights 3D flow, thermal stress, and mechanical stress as key areas for modeling. There is also industry interest in combining machine learning approaches with extrusion technology - see e.g. GreenProtein AI.
Key words: Low-moisture extrusion, high-moisture extrusion
Other Topics
In the interest of time and space, I will not surveyed every possible topic; however, several worthy ones come to mind, including:- Integration of technical and economic modeling for optimization. However, the fusion of technical and economic modeling should be useful to any company evaluating trade-offs between technical projects and economic opportunities. E.g. "should we purchase bioreactor X or Y?" or " should we operate our stirred tank reactor at higher RPM given that energy price is Z?" This is the domain of integrated technical and economic modeling, which is sometimes called ''operations research.'' This kind of work is distinct from techno-economic analysis (TEA), which instead uses technical modeling and assumptions to inform an economic forecast or feasibility estimate. Of course the two are closely related, but a useful simplification is that TEAs are typically external analyses of current technology, while operations research is an internal analysis of current or future technology.
- Genetic engineering and geneomics. Obviously, these are computationally intensive fields and ones that may have an enormous impact on alt proteins. Aside from obvious applications of genetic engineering, gene sequencing has become so cheap that it is plausibly a useful component of a broader high-throughput experimental setup for process development.
- Marketing and social sciences. Data-driven marketing is a massive area of technical research - just ask Google or Meta. This topic is incredibly important to the success of the industry (arguably, more important than all of the topics I have discussed so far put together), and more accessible than some of the more specialized technical areas we have discussed (like CFD or protein engineering). Therefore, it is more than worthy of consideration for any statistically inclined person.
Concluding thoughts
In this survey, I have attempted to give a brief and incomplete overview of some important technical problems in alternative proteins that require in silico expertise. In subsequent articles I hope to raise further problems and go into more detail about the problems discussed here.
As mentioned previously, I believe that in applied work it is necessary to engage deeply with domain experts to have a real impact. Nevertheless, interdisciplinary work is a two-way street, and I believe that alternative proteins researchers and practitioners have much to gain from their colleagues outside of the wet lab as well. With that in mind, I hope that scientists and engineers in all disciplines will engage in more collaborations for the sake of alt proteins’ continued growth and success. We are all depending on you.
About the author
I am a 4th-year Ph.D. student in Computer Science at the Institute for Foundations of Machine Learning at UT Austin. My background is in applied mathematics and statistics. In 2022, I became interested in alternative proteins work and began to look for opportunities to work in this field. However, it was initially difficult for me to find ways to apply my technical skills to this area.
After much research, and many conversations with patient and inviting colleagues, I found concrete problems in the field (mainly in cultivated meat) that I felt I could contribute to. So far, I have worked mainly at the Cultivated Meat Modeling Consortium and at Ark Biotech on problems involving applied optimization and statistics. See this page on my website for more details.
Acknowledgments
My sincere thanks to Dr. Greg Potter (Lipiferm Scientific) for extensive feedback on an earlier version of this article, and to Dr. Rebecca Vaught (Van Heron Labs) for valuable discussions on bioinformatics and metabolic modeling.